Java中Collection与Map详解

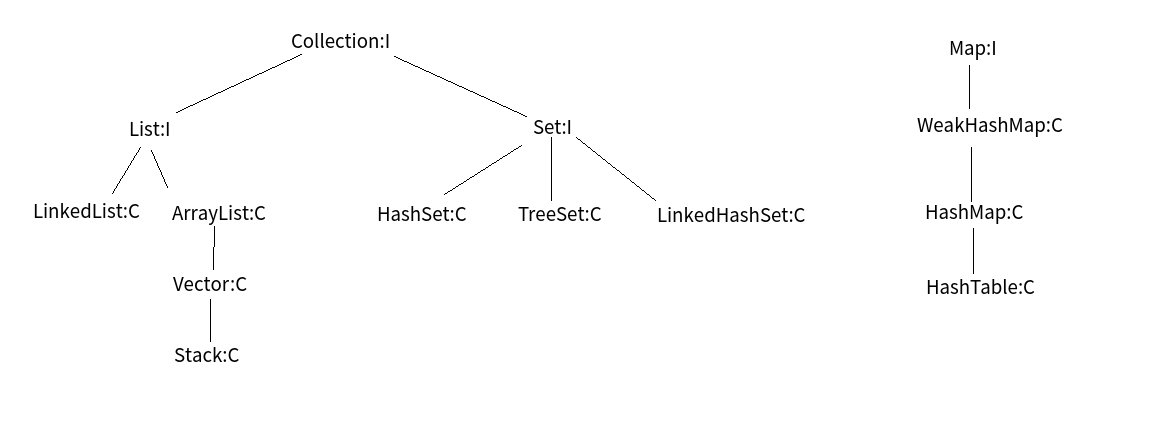
Collection接口
Collection是最基本的集合接口,一个Collection代表一组Object,即Collection的元素(Elements)。一些Collection允许相同的元素而另一些不行。一些能排序而另一些不行。Java SDK不提供直接继承自Collection的类,Java SDK提供的类都是继承自Collection的“子接口”如List和Set。
所有实现Collection接口的类都必须提供两个标准的构造函数:无参数的构造函数用于创建一个空的Collection,有一个Collection参数的构造函数用于创建一个新的Collection,这个新的Collection与传入的Collection有相同的元素。后一个构造函数允许用户复制一个Collection。
如何遍历Collection中的每一个元素?不论Collection的实际类型如何,它都支持一个iterator()的方法,该方法返回一个迭代子,使用该迭代子即可逐一访问Collection中每一个元素。典型的用法如下:
由Collection接口派生的两个接口是List和Set。
1. List接口
List是有序的Collection,使用此接口能够精确的控制每个元素插入的位置。用户能够使用索引(元素在List中的位置,类似于数组下标)来访问List中的元素,这类似于Java的数组。和下面要提到的Set不同,List允许有相同的元素。
除了具有Collection接口必备的iterator()方法外,List还提供一个listIterator()方法,返回一个ListIterator接口,和标准的Iterator接口相比,ListIterator多了一些add()之类的方法,允许添加,删除,设定元素,还能向前或向后遍历。
实现List接口的常用类有LinkedList,ArrayList,Vector和Stack。
LinkedList类
LinkedList实现了List接口,允许null元素。此外LinkedList提供额外的get,remove,insert方法在LinkedList的首部或尾部。这些操作使LinkedList可被用作堆栈(stack),队列(queue)或双向队列(deque)。
注意LinkedList没有同步方法。如果多个线程同时访问一个List,则必须自己实现访问同步。一种解决方法是在创建List时构造一个同步的List:
1List list = Collections.synchronizedList(new LinkedList(...));ArrayList类
ArrayList实现了可变大小的数组。它允许所有元素,包括null。ArrayList没有同步。
size,isEmpty,get,set方法运行时间为常数。但是add方法开销为分摊的常数,添加n个元素需要O(n)的时间。其他的方法运行时间为线性。
每个ArrayList实例都有一个容量(Capacity),即用于存储元素的数组的大小。这个容量可随着不断添加新元素而自动增加,但是增长算法并没有定义。当需要插入大量元素时,在插入前可以调用ensureCapacity方法来增加ArrayList的容量以提高插入效率。 和LinkedList一样,ArrayList也是非同步的(unsynchronized)。
Vector类
Vector非常类似ArrayList,但是Vector是同步的。由Vector创建的Iterator,虽然和ArrayList创建的Iterator是同一接口,但是,因为Vector是同步的,当一个Iterator被创建而且正在被使用,另一个线程改变了Vector的状态(例如,添加或删除了一些元素),这时调用Iterator的方法时将抛出ConcurrentModificationException,因此必须捕获该异常。
Stack 类
Stack继承自Vector,实现一个后进先出的堆栈。Stack提供5个额外的方法使得Vector得以被当作堆栈使用。基本的push和pop方法,还有peek方法得到栈顶的元素,empty方法测试堆栈是否为空,search方法检测一个元素在堆栈中的位置。Stack刚创建后是空栈。
2. Set接口
Set是一种不包含重复的元素的Collection,即任意的两个元素e1和e2都有e1.equals(e2)=false,Set最多有一个null元素。
很明显,Set的构造函数有一个约束条件,传入的Collection参数不能包含重复的元素。
请注意:必须小心操作可变对象(Mutable Object)。如果一个Set中的可变元素改变了自身状态导致Object.equals(Object)=true将导致一些问题。
HashSet
按照哈希算法来存取集合中的对象,存取速度比较快。当向集合中加入一个对象时,HashSet会调用对象的hashCode()
方法来获得哈希码,然后根据这个哈希码进一步计算出对象在集合中的存放位置。哈希表与哈希方法
哈希方法在“键- 值对”的存储位置与它的键之间建立一个确定的对应函数关系 hash() ,使得每一个键与结构中的一个唯一的存储位置相对应:存储位置=hash( 键 )
举一个例子,有一组“键值对”:<5, ”="" tom="">、 <8, ”="" jane="">、 <12, ”="" bit="">、 <17, ”="" lily="">、 <20, ”="" sunny="">,我们按照如下哈希函数对键进行计算 :hash(x)=x%17+3 ,得出如下结果: hash(5)=8 、 hash(8)=11 、 hash(12)=15 、 hash(17)=3 、 hash(20)=6 。我们把 <5, ”="" tom="">、 <8, ”="" jane="">、 <12, ”="" bit="">、 <17, ”="" lily="">、 <20, ”="" sunny="">分别放到地址为 8 、 11 、 15 、 3 、 6 的位置上。当要检索 17 对应的值的时候,只要首先计算 17 的哈希值为 3 ,然后到地址为 3 的地方去取数据就可以找到 17 对应的数据是“ Lily”了,可见检索速度是非常快的。冲突与冲突的解决
通常键的取值范围比哈希表地址集合大很多,因此有可能经过同一哈希函数的计算,把不同的键映射到了同一个地址上面,这就叫冲突。比如,有一组“键- 值对”,其键分别为 12361 、 7251 、 3309 、 30976 ,采用的哈希函数是:123public static int hash(int key){return key%73+13420;}则将会得到hash(12361)=hash(7251)=hash(3309)=hash(30976)=13444 ,即不同的键通过哈希函数对应到了同一个地址,我们称这种哈希计算结果相同的不同键为同义词。此时再换用另一种哈希函数计算.换言之,当存在多个键通过哈希计算结果相同时,会再选用另一个哈希计算直到不存在重复地址为止.
我们还应该注意,Java语言对equals()的要求如下,这些要求是必须遵循的:
? 对称性:如果x.equals(y)返回是“true”,那么y.equals(x)也应该返回是“true”。
? 反射性:x.equals(x)必须返回是“true”。
? 类推性:如果x.equals(y)返回是“true”,而且y.equals(z)返回是“true”,那么z.equals(x)也应该返回是“true”。
? 还有一致性:如果x.equals(y)返回是“true”,只要x和y内容一直不变,不管你重复x.equals(y)多少次,返回都是“true”。
? 任何情况下,x.equals(null),永远返回是“false”;x.equals(和x不同类型的对象)永远返回是“false”。
以上这五点是重写equals()方法时,必须遵守的准则,如果违反会出现意想不到的结果,请大家一定要遵守hashCode方法默认返回对象的地址,String,Integer等封装类型对它进行了重写返回一个整数
该整数的取值来自于当前字符串的每个字母的编码值.公示如下123public int hashCode(){return “abcde”.hashCode();}比如有一个字符串“abcde”,采用31进制的计算方法来计算这个字符串的总和,你会写出下面的计算式子:
a31^4+b31^3+c31^2+d31^1+e31^0.注意,这里的a,b,c,d或者e指的是它们的ASCII值.
那么为什么选用31作为基数呢?先要明白为什么需要HashCode.每个对象根据值计算HashCode,这个code大小虽然不奢求必须唯一(因为这样通常计算会非常慢),但是要尽可能的不要重复,因此基数要尽量的大。另外,31N可以被编译器优化为左移5位后减1,有较高的性能.在Object类中定义了hashCode()方法和equals()方法,Object类的equals()方法按照内存地址比较对象是否相等,因此如果object.equals(object2)为true, 则表明object1变量和object2变量实际上引用同一个对象,那么object1和object2的哈希码也肯定相同。
为了保证HashSet能正常工作, 要求当两对象用equals()方法比较的结果为true时,它们的哈希码也相等。如果用户定义的Customer类覆盖了Object类的equals()方法,但是没有覆盖Object类的hashCode()方法,就会导致当customer1.equals(customer2)为true时,而customer1和customer2的哈希码不一定一样,这会使HashSet无法正常工作。
1234567891011121314151617181920212223242526272829public class Customer {private String name;private int age;public Customer(String name, int age) {this.name = name;this.age = age;}public String getName() {return name;}public int getAge() {return age;}public boolean equals(Object o) {if(this==o) return true;if(!(o instanceof Customer)) return false;Customer other = (Customer)o;if(this.name.equals(other.getName()) && this.age.equals(other.getAge())return true;elsereturn false;}}
以下程序向HashSet中加入两个Customer对象。
出现以上原因在于customer1和customer2的哈希码不一样,因此为两为customer对象计算出不同的位置,于是把它们放到集中中的不同的地方。应加入以下hashCode()方法:
HashSet中元素比较执行顺序是先执行hashCode(),如果是对象(类类型),使用对象的地址进行hashCode(),不同对象hashCode出来的值不同(默认hashCode方法会使用不同算法直到值不同为止),如果是基本类型,则会比较基本类型的值。
TreeSet
TreeSet实现了SortedSet接口,能够对集合中的对象进行排序。当TreeSet向集合中加入一个对象时,会把它插入到有序的对象序列中。那么TreeSet是如何对对象进行排序的呢?TreeSet支持两种排序方式:自然排序和客户化排序。默认情况TreeSet采用的是自然排序方式:自然排序 升序 默认返回负数
当前和传入的比较返回 升序
传入和当前的比较返回 降序String类型比较大小,使用compareTo(Object obj)方法.
在JDK类库中, 有一部分类实现了Comparable接口,如Integer、Double和String等。Comparable接口有一个
compareTo(Object o)方法,它返回整数类型。对于x.comapreTo(y), 如x表示第一个值 y表示第二个值
返回0, 表明 x和y相等
返回值大于0, 表明 x>y 1
返回值小于0, 表明 x<y -1例如:
当前类型12345678Student implements Comparable {int age;public int compareTo(Object obj) {Student stu = (Student)obj;return age-stu.age;当前age-传入对象的age 自然排序stu.age-age;传入对象的age-当前age 降序排序}}TreeSet调用对象的compareTo()方法比较集合中对象的大小,然后进行升序排序,这种排序方式称为自然排序。
JDK类库中实现了Comparable接口的一些类的排序方式:
| 类型 | 排序方式 |
|—–|—–|
| Byte, Short, Integer, Long, Double, Float | 按数字大小排序 |
| Character | 按字符的Unicode值的数字大小排序 |
| String | 按字符串中字符的Unicode值排序 |
使用自然排序, TreeSet中只能加入相同类型对象,且这些对象必须实现了Comparable接口。否则会抛出ClassCastException异常。最适合TreeSet排序的是类的内容可以操作,可以修改限定类的内容.
客户化排序
除了自然排序外, TreeSet还支持客户化排序。java.util.Comparator接口提供了具体的排序方法, 它有一个compare(Object x, Object y)方法,用于比较两个对象的大小
如果希望TreeSet按照Customer对象的name属性进行降序排列,可以先创建一个实现Comparator接口的类 CustomerComparator, 参见:
使用compare(Object o1,Object o2)进行比较,一定要o1.compare(o2).如果想保持当前顺序,返回-1,如果想更改当前的顺序.返回1
compare(Object o1,Object o2) { o1.compare(o2)>0 return -1 时 表示降序 o1.compare(o2)<0 return 1 时 表示降序 o1.compare(o2)>0 return 1时 表示升序 o1.compare(o2)<0 return -1时 表示升序 }1234567891011121314151617181920212223242526272829import java.util.*;public class CustomerComparator implements Comparator {public int compare(Object o1, Object o2) {Customer c1 = (Customer)o1;Customer c2 = (Customer)o2;if(c1.getName().compareTo(c2.getName())>0) return -1;if(c1.getName().compareTo(c2.getName())<0) return 1;return 0;}public static void main(String[] args) {Set set = new TreeSet(new CustomerComparator());Customer customer1 = new Customer("Tom",15);Customer customer3 = new Customer("Jack",16);Customer customer2 = new Customer("Mike",26);set.add(customer1);set.add(customer2);set.add(customer3);Iterator it = set.iterator();while(it.hasNext()) {Customer customer = it.next();System.out.println(customer.getName() + " " + customer.getAge());}}}打印输出: Tom 15 Mike 26 Jack 16LinkedHashSet
具有HashSet的查询速度,且内部使用链表维护元素的顺序(插入的次序)。于是在使用迭代器遍历Set时,结果会按元素插入的次序显示。
3. Map接口
请注意,Map没有继承Collection接口,Map提供key到value的映射。一个Map中不能包含相同的key,每个key只能映射一个value。Map接口提供3种集合的视图,Map的内容可以被当作一组key集合,一组value集合,或者一组key-value映射,只能通过entrySet()获取set实例,进而进行遍历,Map没有实现itrator,不能使用增强for循环.
Hashtable类
Hashtable继承Map接口,实现一个key-value映射的哈希表。任何非空(non-null)的对象都可作为key或者value。
添加数据使用put(key, value),取出数据使用get(key),这两个基本操作的时间开销为常数。Hashtable通过initial capacity和load factor两个参数调整性能。通常缺省的load factor 0.75较好地实现了时间和空间的均衡。增大load factor可以节省空间但相应的查找时间将增大,这会影响像get和put这样的操作。
使用Hashtable的简单示例如下,将1,2,3放到Hashtable中,他们的key分别是”one”,”two”,”three”:
1234Hashtable numbers = new Hashtable();numbers.put(“one”, new Integer(1));numbers.put(“two”, new Integer(2));numbers.put(“three”, new Integer(3));要取出一个数,比如2,用相应的key:
12Integer n = (Integer)numbers.get(“two”);System.out.println(“two = ” + n);由于作为key的对象将通过计算其散列函数来确定与之对应的value的位置,因此任何作为key的对象都必须实现hashCode和equals方法。hashCode和equals方法继承自根类Object,如果你用自定义的类当作key的话,要相当小心,按照散列函数的定义,如果两个对象相同,即obj1.equals(obj2)=true,则它们的hashCode必须相同,但如果两个对象不同,则它们的hashCode不一定不同,如果两个不同对象的hashCode相同,这种现象称为冲突,冲突会导致操作哈希表的时间开销增大,所以尽量定义好的hashCode()方法,能加快哈希表的操作。
如果相同的对象有不同的hashCode,对哈希表的操作会出现意想不到的结果(期待的get方法返回null),要避免这种问题,只需要牢记一条:要同时复写equals方法和hashCode方法,而不要只写其中一个。Hashtable是同步的。
HashMap类
HashMap和Hashtable类似,不同之处在于HashMap是非同步的,并且允许null,即null value和null key。,但是将HashMap视为Collection时(values()方法可返回Collection),其迭代子操作时间开销和HashMap的容量成比例。因此,如果迭代操作的性能相当重要的话,不要将HashMap的初始化容量设得过高,或者load factor过低。
WeakHashMap类
WeakHashMap是一种改进的HashMap,它对key实行“弱引用”,如果一个key不再被外部所引用,那么该key可以被GC回收。
SortedMap类
有序的,按照key值的自然排序规则或者在创建SortedMap集合时指定的Comparator进行排序。
总结
如果涉及到堆栈,队列等操作,应该考虑用List,对于需要快速插入,删除元素,应该使用LinkedList,如果需要快速随机访问元素,应该使用ArrayList。
Tips:
Collection 和 Collections的区别。
Collections是个java.util下的类,它包含有各种有关集合操作的静态方法。
Collection是个java.util下的接口,它是各种集合结构的父接口。List, Set, Map是否继承自Collection接口?
List,Set是 Map不是
ArrayList和Vector的区别。
一.同步性:Vector是线程安全的,也就是说是同步的,而ArrayList是线程序不安全的,不是同步的
二.数据增长:当需要增长时,Vector默认增长为原来一培,而ArrayList却是原来的一半HashMap和Hashtable的区别
一.历史原因:Hashtable是基于陈旧的Dictionary类的,HashMap是Java 1.2引进的Map接口的一个实现
二.同步性:Hashtable是线程安全的,也就是说是同步的,而HashMap是线程序不安全的,不是同步的
三.值:只有HashMap可以让你将空值作为一个表的条目的key或value